検証可能なAI
AIのトレーニングと推論の問題点
AIの急速な発展は画期的な進歩をもたらし、世界中の数え切れないほどの産業を変革しています。しかし、この進歩は強力である一方で不透明な「ブラックボックス」システムも生み出しました。これらのモデルのトレーニングと推論のプロセスはしばしば透明性に欠け、特定の結論に至る経緯を監査することを困難にしています。この不透明性は、根本的な説明責任の欠如を生み出します。AIが重大なエラーを犯した際に、原因を特定したり責任を割り当てたりすることは大きな課題です。
この透明性の欠如は、著作権で保護された素材と著しく類似したコンテンツを生成したとして大きな反発に直面している生成AIの分野で特に顕著です。中心的な問題は出所(プロビナンス)です。トレーニングに使用されたデータセットが開示されないことが多いため、モデルが保護された著作物でトレーニングされたかどうかを検証することは不可能です。これは重大な法的リスクを生み出し、アーティスト、作家、その他のコンテンツ制作者の信頼を損ないます。
さらに、公平性の確保も重要な課題です。AIモデルは、特に銀行や採用などの機密性の高いアプリケーションにおいて、有害なバイアスを示すことがあります。検証可能なプロセスがなければ、トレーニングデータに内在するバイアスと、データ汚染攻撃によって悪意を持って誘発されたバイアスとを区別することはほぼ不可能です。モデルの完全性を監査できないこの状況は、重要な決定においてその出力を信頼することを困難にします。
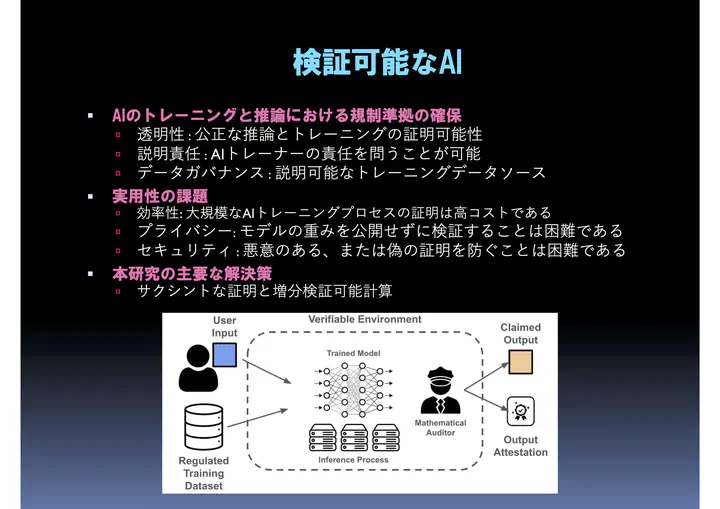
透明性と説明責任を持つAIのための検証可能なAI
計算理論と応用暗号技術の研究は、AIにおけるこれらの信頼に関連する問題への対処にますます焦点を当てています。例えば、トレーニングのゼロ知識証明 (Zero-Knowledge Proof of Training) は、トレーニングプロセス全体を検証するために設計された暗号技術であり、承認されたデータセットに紐付いていることを保証します。このような証明を要求することで、著作権侵害の主張のような複雑な問題を監査し、暗号技術的に解決できる可能性があります。
しかし、数十億のパラメータを持つモデルのトレーニングプロセス全体を検証することは、計算上非常に困難なタスクです。これを軽減するには、検証可能なAIをスケールさせるための洗練された解決策を見つけるために、学際的な協力が必要です。
私たちの研究室では、透明性、説明責任、データガバナンスの問題に取り組むため、学際的な知識を応用し、特にサクシントな証明 (Succinct Argument) や増分検証可能計算 (Incrementally Verifiable Computation) と呼ばれる技術を適用して、複数のアプローチを研究しています。